How SEO is needed for your website.
Google Search is a fully-automated search engine that uses software known as web crawlers that explore the web regularly to find pages to add to our index.

You manage and maintain your website, you may come across more unique scenarios that affect Google Search. This guide covers more in-depth SEO tasks, such as preparing for a site move or managing a website.
you usually don't even need to do anything except post your site on the web. However, sometimes sites get missed. Check to see if your site is on Google and learn how to make your content more visible in Google Search.Google automatically looks for sites to add to our index.
Google Search works in three stages, and not all pages make it through each stage:
1.Crawling: Google downloads text, images, and videos from pages it found on the internet with automated programs called crawlers.
2.Indexing: Google analyzes the text, images, and video files on the page, and stores the information in the Google index, which is a large database.
3.Serving search results: When a user searches on Google, Google returns information that's relevant to the user's query.

Duplicate content
Be sure that you understand what canonical pages are, and how they affect crawling and indexing of your site.
Help Google choose the right canonical URL for your duplicate pages
bookmark_border
If you have a single page that's accessible by multiple URLs, or different pages with similar content (for example, a page with both a mobile and a desktop version), Google sees these as duplicate versions of the same page. Google will choose one URL as the canonical version and crawl that, and all other URLs will be considered duplicate URLs and crawled less often.
If you don't explicitly tell Google which URL is canonical, Google will make the choice for you, or might consider them both of equal weight, which might lead to unwanted behavior, as explained in Reasons to choose a canonical URL.
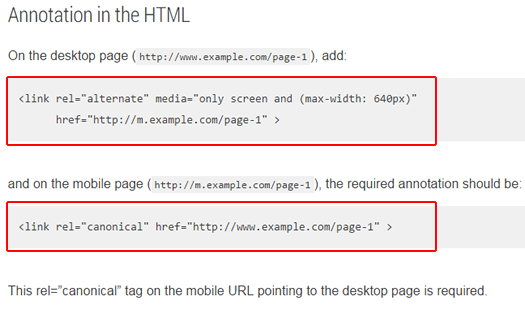
How Google indexes and chooses the canonical URL
When Google indexes a site, it tries to determine the primary content of each page. If Google finds multiple pages on the same site that seem to be the same, it chooses the page that it thinks is the most complete and useful, and marks it as canonical. The canonical page will be crawled most regularly; duplicates are crawled less frequently in order to reduce the crawling load on your site.
Google chooses the canonical page based on a number of factors (or signals), such as whether the page is served via HTTP or HTTPS, page quality, presence of the URL in a sitemap, and any rel=canonical labeling. You can indicate your preference to Google using these techniques, but Google may choose a different page as canonical than you do, for various reasons.

Different language versions of a single page are considered duplicates only if the main content is in the same language (that is, if only the header, footer, and other non-critical text is translated, but the body remains the same, then the pages are considered to be duplicates).
Google uses the canonical pages as the main sources to evaluate content and quality. A Google Search result usually points to the canonical page, unless one of the duplicates is explicitly better suited for a user. For example, the search result will probably point to the mobile page if the user is on a mobile device, even if the desktop page is marked as canonical.
Control what you share with Google
bookmark_border
Control what information Google sees on your site and what is shown in search results. There are a few reasons you might want to hide content from Google:
To keep data private: You might have private data hosted on your site that you want to keep other users from accessing. You can block Google from crawling such data so it doesn't show up in search results.
To hide content of less value to your audience:
Your website might have the same content in different places, which could negatively affect your page rankings in Google Search. A good example of where duplicate content can arise is a site-wide search function to help users navigate site content.
Some search functions generate and display custom search results pages every time any user enters a query. Google can crawl all the custom search results pages individually if they are not blocked. As a result, Google sees a site with many similar pages and might categorize the duplicate content as spam, which could undermine page rankings in Google Search.
Your website might share information generated by other third-party sources, which is available in other places on the web. Google sees less value in including your pages that include large amounts of duplicate content in Google Search results. You can block the copied content to improve what Google sees and boost your page rankings in Google Search.
To have Google focus on your important content: If you have a very large site (many thousands of URLs) and pages with less important content, or if you have a lot of duplicate content, you might want to prevent Google from crawling the duplicate or less important pages in order to focus on your more important content.
How to block content
Here are the main ways to block content from appearing in Google:
Methods
Remove the content
For all content types
Removing content from your site is the best way to ensure that it won't appear in Google Search, or anywhere. If the information is already appearing in Google, you might need to take additional steps to make your removal permanent.
Password-protect your files
For all content types
If you have confidential or private content that you don't want to appear in Google search results, the simplest and most effective way to block private URLs from appearing is to store them in a password-protected directory on your site server. Googlebot and all other web crawlers are unable to access content in password-protected directories.
Advanced users: If you're using Apache Web Server, you can edit your .htaccess file to password-protect the directory on your server. There are a lot of tools on the web that can help you do this.
robots.txt and/or emergency image removal request
For images
Use robots.txt rules to block images.
noindex directive
For web pages
noindex is a technique that tells Google not to read your page or let it appear in Google search results. Your pages can still be linked to and visited through other web pages, or directly visited by users with a link, but the pages will not appear in Google search results. This method requires technical savvy, and may not be available if you use a content management system to host your site.
Opt out of specific Google properties
For web pages
You can tell Google not to include content from your site in specific Google properties, rather than all Google properties.
nosnippet meta tag
For Search result snippets
Add thetag to your page's HTML head section to prevent a snippet from appearing in Search. However, note that this can generate a confusing message in search results ("No information is available for this page").
Resources
Be sure that any resources (images, CSS files, and so on) or pages that Google is meant to crawl are accessible to Google; that is, they are not blocked by any robots.txt rules and are accessible to an anonymous user. Inaccessible pages will not appear in the Index Coverage report, and the URL Inspection tool will show them as not crawled. Blocked resources are shown only at the individual URL level, in the URL Inspection tool. If important resources on a page are blocked, this can prevent Google from crawling your page properly. Use the URL Inspection tool to render the live page to verify whether Google sees the page as you expect.
Robots.txt
Use robots.txt rules to prevent crawling, and sitemaps to encourage crawling. Block crawling of duplicate content on your site, or unimportant resources (such as small, frequently used graphics such as icons or logos) that might overload your server with requests. Don't use robots.txt as a mechanism to prevent indexing; use the noindex tag or login requirements for that. Read more about blocking access to your content.
Sitemaps
Sitemaps are a very important way to tell Google which pages are important to your site, and also provide additional information (such as update frequency), and are very important for crawling non-textual content (such as images or video). Although Google won't limit crawling to pages listed in your sitemaps, it will prioritize crawling these pages. This is especially important for sites with rapidly changing content, or with pages that might not be discovered through links. Using sitemaps helps Google discover and prioritize which pages to crawl on your site. Read all about sitemaps here.
Internationalized or multi-lingual sites
If your site includes multiple languages, or is targeted at users in specific locales:
Read about multi-regional and multi-lingual sites for high-level advice on how to manage sites that have localized content for different languages or regions.
Use hreflang to tell Google about different language variations of pages on your site.
If your site adapts the content of its pages based on the locale of the request, read how this can affect Google's crawl of your site.
Migrating a page or a site
On the occasion that you might need to move a single URL or even a whole site, follow these guidelines:
Migrating a single URL
If you move a page permanently to another location, don't forget to implement 301 redirects for your page. If the move is only temporary for some reason, return 302 instead to tell Google to continue to crawl your page.
When a user requests a page that has been removed, you can create a custom 404 page to provide a better experience. Just be sure that when a user requests a page that is no longer there, you return a true 404 error, not a soft 404.
Migrating a site
If you're migrating an entire site, implement all the 301 and sitemap changes you need, then tell Google about the move so that we can start crawling the new site and forwarding your signals to the new site. Learn how to migrate your site.
Follow crawling and indexing best practices
Make your links crawlable. Google can follow links only if they are an tag with an href attribute. Links that use other formats won't be followed by Google's crawlers. Google cannot follow links without an href tag or other tags that perform as links because of scripted click events.
Use rel=nofollow for paid links, links that require login, or untrusted content (such as user-submitted content) to avoid passing your quality signals on to them, or having their bad quality reflect on you.
Managing your crawl budget: If your site is particularly large (hundreds of millions of pages that change periodically, or perhaps tens of millions of pages that change frequently), Google might not be able to crawl your entire site as often as you'd like, so you might need to point Google to the most important pages on your site. The best mechanism for doing so at present is to list your most recently updated or most important pages in your sitemaps, and hiding your less important pages using robots.txt rules.
JavaScript usage: Follow Google's recommendations for JavaScript on websites.
Multi-page articles: If you have an article broken into several pages, be sure that there are prominent next and previous links for users to click (and that these are crawlable links). That's all you need for the page set to be crawled by Google.
Infinite scroll pages: Google can have trouble scrolling through infinite scroll pages; provide a paginated version if you want the page to be crawled. Learn more about search-friendly infinite scroll pages.
Block access to URLs that change state, such as posting comments, creating accounts, adding items to a cart, and so on. Use robots.txt to block these URLs.
Review the list of which file types are indexable by Google.
In the unlikely situation that Google seems to be crawling your site too much, you can turn down the crawl rate for your site. However, this should be a rare occurrence.
If your site is still HTTP, we recommend migrating to HTTPS, for your users' security, as well as your own.
Help Google understand your site
Put key information in text, not graphics, on the site. Although Google can parse and index many file types, text is still the safest bet to help us understand the content of the page. If you use non-text content, or if you want to provide additional guidance about the content of the site, add structured data to your pages to help us understand your content (and in some cases, provide special search features such as rich results).
If you feel comfortable with HTML and basic coding, you can add structured data by hand following the developer guidelines. If you want a little help, you can use the WYSIWYG Structured Data Markup helper to help you generate basic structured data for you.
If you don't have the ability to add structured data to your pages, you might use the Data Highlighter tool, which lets you highlight portions of a page and tell Google what each section represents (an event, a date, a price, and so on). This is simple, but it can break if you change the layout of your page.
Read more about helping Google understand your site content.
Follow our guidelines
Caution: Be sure to follow our Webmaster Guidelines. Some of these are recommendations and best practices; others can lead to a site being removed from the Google index if you do not follow them.
Content-specific guidelines
If you have specific types of content on your site, here are some recommendations for getting them on Google in the best way:
Video: Be sure to follow our video best practices to enable Google to find, crawl, and show results for videos hosted on your site.
Podcasting: You can expose podcasts to Google by following these guidelines.
Images: Follow our image best practices to get your images to appear in Search. You can show additional information about your image in Google Images by providing image rights metadata on the image host page. To block an image from being indexed, use a robots.txt Disallow rule.
For children: If your content is specifically for children, tag your pages or site as child-directed in order to comply with the Children's Online Privacy Protection Act (COPPA).
Adult sites: If your site (or specific pages) contain adult-only content, you might consider tagging it as adult content, which will filter it in SafeSearch results.
News: If you run a news site, here are some important considerations:
If you have news content, be sure to read the Google Publisher Center help documentation.
In addition, create a News sitemap to help Google discover content more quickly.
Be sure to prevent abuse on your site.
If you want to provide a limited number of views to visitors without a subscription or login, read about flexible sampling to learn some best practices about providing limited access to your content.
See how to indicate subscription and paywalled content on your site to Google while still enabling crawling.
See how to use meta tags to limit text or image use when generating search result snippets.
Consider using AMP or Web Stories for fast-loading content.
Other sites (for example, sites about businesses, books, apps, scholarly works): See other Google services where you can post your information.
See if Google supports a Search feature specific for your content type. Google supports specialized Search features for recipes, events, job posting sites, and more.
Manage the user experience
Providing a good user experience should be your site's top goal, and a good user experience is a ranking factor. There are many elements to providing a good user experience; here are a few of them.
Google recommends that websites use HTTPS, rather than HTTP, to improve user and site security. Sites that use HTTP can be marked as "not secure" in the Chrome browser. Learn how to secure your site with HTTPS.
A fast page usually beats a slow page in user satisfaction. You can use the Core Web Vitals report to see your site-wide performance numbers, or PageSpeed Insights to test performance for individual pages. You can learn more about building fast pages on the web.dev site. Also consider using AMP for fast pages.
Mobile considerations
With mobile searches now exceeding desktop searches, it's important that your site be mobile-friendly. Google now uses a mobile crawler as the default crawler for websites. Read about how to make your site mobile friendly.
Read these additional pages about mobile usage on Google, including behavior on feature phones, how Google Discover works on mobile devices, and also guidelines about announcing any mobile billing charges clearly on your site to prevent warnings in Google Chrome.
Control your search appearance
Google provides many kinds of search result features and experiences in Google Search, including review stars, embedded site search boxes, and special result types for specific types of information such as events or recipes. See which ones are appropriate for your site and consider implementing them. You can provide a favicon to show in search results for your site. You can also provide an article date to appear in search results.
Be sure to read the articles on how to help Google provide good titles links and snippets. You can also restrict the snippet length, or omit it entirely if you wish. See how to use meta tags to limit text or image use when generating search result snippets.
If you are a European press publisher, tell Search Console.
Using Search Console
Search Console offers a broad range of reports to help you monitor and optimize your site performance on Google Search. Learn more about what reports to use.















